
Dark data and data black holes: Why entrepreneurs and CEOs should care
Balaji Padmanabhan
1543238670713.png?mode=crop&crop=faces&ar=1%3A1&format=auto&w=1920&q=75)
Wednesday November 28, 2018 , 12 min Read

Much of the entrepreneurial activity today is centred around leveraging the power of digitisation to unlock new sources of value creation and appropriation. While it is no secret that businesses today are skilled at gathering data and information, many are still unable to unlock the vast potential of the data they’ve gathered. This yet-to-be harnessed data, referred to as ‘dark data,’ offers entrepreneurs the ability to create value. As do ‘data black holes.’ Find out why entrepreneurs and CEOs should care.

The invention of the microscope and telescope in 1600s dramatically changed what we now know about biology and astronomy. Similarly, advances in information technology (IT) are creating new opportunities for understanding customer behaviour and competitive advantage.
It is no surprise that much of the entrepreneurial activity these days leverages the power of IT and digitisation to unlock new sources of value creation and appropriation. But increasingly, this value creation is expected to emerge from two interesting ways of thinking about data-driven entrepreneurship: dark data and data black holes.
Unlocking the value of dark data
Just as the invention of microscopes made it possible to study biological structures and cells, big data and analytics now make it possible to quantify human activities and behaviours at a much more granular level than ever before. That, in turn, creates opportunities for entrepreneurs to identify ways of discovering new actionable data and metrics that are as yet part of tacit knowledge.
Dark data in this context refers to data that is yet to be harnessed through newer technologies such as machine learning algorithms to create new value.
One example of entrepreneurship based on leveraging the potential of dark data comes from a 2014 New York Times article about an analytics-driven basketball trainer, who sometimes slept in the couch in Kevin Durant’s home. Durant, one of the stars of the National Basketball Association, went on to win the league’s Most Valuable Player award that year. The trainer was Justin Zormelo, a young math and data savvy entrepreneur, who started Best Ball Analytics, a company dedicated to using analytics in sports.
One of the key data points Zormelo used to analyse the game was video recordings of basketball games. He used data from videos to identify patterns such as how high a player jumps could affect the likelihood of making a shot, or how a player may miscalculate when to jump while looking to pass – often a cardinal mistake in a sport where tiny errors can make the difference between a championship or a loss. Insights such as the ones Zormelo gleaned exemplify the value that can be unlocked by paying attention to information that lies below the surface, otherwise referred to dark data.

While on the surface, data within videos may seem obvious to a lay human observer, much of it is in fact “dark” and requires analyses by machine learning algorithms. Videos are bit streams, and while extracting patterns automatically from raw video files is hard, it offers significantly valuable insights. To put it in perspective, it is estimated that one billion hours of YouTube videos are watched each day, yet most of the data within them is “dark” and unavailable for analytics.
For entrepreneurs, there is a significant opportunity to creatively think what questions can be answered or problems solved by leveraging dark data.
For instance, thanks to teenagers uploading videos every day, marketers today have access to details about their taste in fashion and music, as well as new attitudes and communication styles taking shape worldwide.
And so, the question is: can startups mine this dark data and provide marketers with hyper-localised real-time intelligence on consumer tastes and preferences?
Researchers at Google and other leading technology firms are pushing the boundaries when using deep-learning based methods to mine dark data in videos. Convolutional Neural Networks, for instance, have proven effective in automatically classifying a YouTube video into the sport that the video is about. Facebook is using machine learning to detect if an uploaded video on its platform could be fake.
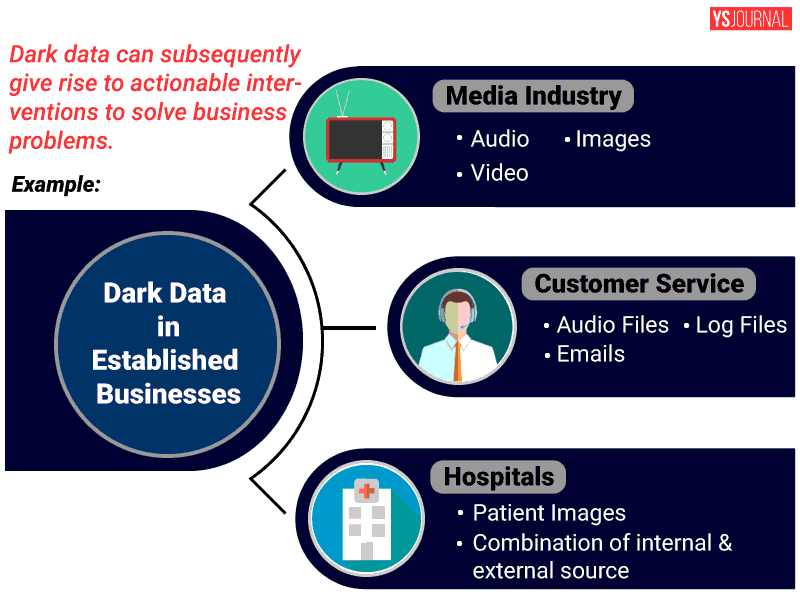
Dark data is also plentiful in established businesses. The media industry, with its billions of hours of proprietary audio, image and video data, is ripe for transformation by shining light onto their content. Likewise, most firms record their customer calls, resulting in billions of minutes of customer service audio files. Hospitals also capture millions of patient images every day, as physicians seek scans to diagnose and treat various illnesses.
Sometimes, the full potential of dark data is realised by combining existing datasets from internal or external sources -- to pose questions that were never asked earlier or to create a visualisation of interesting associations that can subsequently give rise to actionable interventions to solve business problems.
To be clear, we have come a long way with meta-data as a coarse proxy for the rich content inside much of today’s dark data. Meta-data on YouTube videos, for instance, has basic information including title, length, genre, author and viewer comments.
It’s time for entrepreneurs and businesses to dive in and build deeper, better methods and solutions to unlock the true value in these and similar data assets.
Data black holes and the right to be forgotten
Mathematical functions often have inverses, which reverse the effect that a function might otherwise have. Dark data also have their inverse – the data black hole.
Just as we see dark data coming to light today, we are also starting to witness otherwise visible data get sucked into black holes and away from prying algorithms.
One such example of data black hole is the “right to be forgotten”, part of the recent General Data Protection Regulation (GDPR) enacted in Europe in 2017. GDPR provides individuals the right to ask for their data to be deleted in some circumstances.
As data privacy continues to evolve, we see more places that might impose such constraints, which effectively will create a world with many small and large data black holes.
And yet, data black holes represent opportunities for entrepreneurs and businesses.
Systems that can help companies effectively comply with regulation will be in high demand. In some cases, there might also be opportunities to extract some generalisable insights from data being sucked into a black hole. While we may lose forever data about a customer’s extended viewing behaviour of say The Big Bang Theory TV show, there may be labels such as interest in science-fiction comedy series, based on summaries or models that were built on data going into the black hole, which can, in turn, be used as proxies in scenarios where the law allows it.

Sometimes, data that was otherwise previously broadly accessible might be moved to make it more restrictive.
For instance, data localisation laws, such as the ones being considered in India, might make global corporations store data locally. While the issue of where data is stored and where it is visible are two orthogonal issues, it is conceivable that local entrepreneurs see opportunities to mine local data or provide services to global firms to help them adapt to local regulations. New data privacy startups such as US-based Prifender and WireWheel are doing just this and have recently raised $20 million in their bid to become the industry standard in privacy compliance.
Still, in an era where privacy concerns and regulations might make customer data more difficult to access, entrepreneurs need to think creatively about doing a 180-degree pivot – from building solutions to mine massive customer data to developing methods to protect customer data and ensure data privacy.
From data to insights and value
There are various ways for businesses to leverage the power of dark data and data black holes using new and emerging technologies. Deep-learning based methods, in particular, are popular today, and have demonstrated the ability to extract insights from vast amounts of training data.
These methods are driving a new wave of computer vision innovation that could one day be the eyes through which a blind person sees the world. Today, these technologies are able to automatically process an image and identify it, including a frisbee being thrown in a park. This means, we may not be too far from a time when robots may be able to scan a swimming pool and jump in immediately to save a person who may have fallen in.
For example, US-based onQ, an innovative startup that we are working with, has a video tagging platform that allows users to post a comment or an emoji on the timeline while watching the video. Based on the exact moments of user engagement, the system can identify and provide specific and related insights. In contrast to heavily algorithmic approaches, onQ’s approach is intuitive and design-oriented. Their tool provides an overlay on top of any video that captures interactions with the content; this, in turn, creates new structured data that can be leveraged further to add significant value from otherwise dark data.
Deep-learning based models, however, need to be trained, and often, quite extensively, to ensure it's useful. This does favour larger incumbents with access to the kind of labeled data that can help build models to unlock dark data. It is not surprising, therefore, to see technology giants such as Google, Baidu, Microsoft, Alibaba or Facebook pushing the envelope when it comes to deep-learning based models.
Yet, online crowdsourcing platforms such as Mechanical Turk provide an opportunity for a startup with relatively modest funding or resources to build innovative proof-of-concepts that can attract deeper investment or buyouts. For instance, Apple last year acquired Lattice Data, a startup that was specialising in algorithms to shed light on dark data.
To be clear, this trend of acquiring companies that bring to light otherwise-inaccessible data has a relatively long history. In 2010, eBay acquired an early-stage company called Milo for $75 million. Milo's product was bringing to light in-store product inventory data from brick and mortar retail stores.
Similarly, back in 1950, Nielsen built a version of the “audiometer” to measure what people watch on television – data that was dark then. In the decades since its launch, this invention has revolutionised the programming and advertising industries.
Startups and big business alike should, therefore, take inspiration from such time-tested business models aimed at unlocking the value of dark data.
Managing data assets
And yet, most of the dark data assets that existing enterprises have cannot be stored in the traditional relational database form. Instead, they require significant big data infrastructure and expertise, which many firms lack. As such, it is more likely than not that such data assets are being systematically ignored due to the complexities of managing them.
Many of our traditional businesses today need a different way of thinking about their dark data assets. But even as level one firms such as Google and Facebook build out the technology through their own internal use cases, we are slowly seeing more widely accessible solutions being made available in the market. Deep learning libraries such as Keras and Tensor Flow are examples of this, and there will be even more applied innovations that will be accessible for more traditional businesses.
A few of these traditional businesses will likely build game-changing solutions that can legitimately be spun off as separate entities that drive enormous shareholder value. Healthcare is one such sector where we may see unicorns arise. However, luck favours the prepared, and those businesses that invest today in long-term strategies for managing dark data and data black holes will see related rewards.

Lessons on data-driven entrepreneurship
For entrepreneurs, an understanding of dark data and data black holes in their specific domains can provide new ways of thinking about value creation and appropriation.
An identification of new data and related metrics will, in turn, allow entrepreneurs to explore and tap opportunities to become service providers of such data with specific prescriptions to those who may benefit from that. Which is exactly what Justin Zormelo did.
Others may want to focus on creating newer technologies to more easily visualise or aggregate that data while leaving the prescription for others to handle.
For CEOs, the challenge may be to sensitise their organisations about new ways of measuring and monitoring performance of their business operations. A narrow focus on existing metrics can often blindside an organisation to newer opportunities.
CEOs also need to avoid the temptation to protect their current revenue streams by killing newer potentially promising revenue streams. For example, Microsoft reportedly killed its Keywords project in 2000 after a brief experimentation, fearing that this new business may cannibalise other revenue streams. Microsoft repeated this mistake later when it decided not to buy online-advertising company Overture in 2003.
Indeed, an understanding of dark data and data black holes is just the first step toward data-driven entrepreneurship.
More importantly, businesses need to explore what to do with the data when it becomes visible or goes dark. While first-order use cases of such data promise significant value, it is the second- and higher-order use cases that could drive exponential value.
New data that comes to light is now accessible to an increasingly connected world using artificial intelligence (AI) technology. Entities such as British AI firm DeepMind have been demonstrating the capabilities of modern AI software. These firms have been breaking through many barriers of what humans thought that software was ever capable of.
Combining these ideas with the now 'bright' data will unleash a wave of innovations unlike any we have ever seen before.