

Breakthrough new AI software can interpret and caption photos for humans and machines

I have always shied away from terming SnapShopr as only an image recognition company. We are and will be an artificial intelligence (AI) company with strong foundation in research. When we first started Snapshopr, we knew that we had the necessary knowledge and expertise to build world-class technology that truly impacts people’s lives and this is one of the moments we would define as a breakthrough.
As part of Project Turing at Snapshopr Research, our research unit, we began with building a state-of-the-art image captioning system from scratch and recently achieved the top rank from Asia in a global AI competition known as MS COCO challenge. We applied our learning from there to build an early prototype of a Visual Q&A system to solve the Visual Turing test, a modification of the original Turing test . This kind of visual description task could be used to assess a machine’s intelligence relative to a human . For the sake of simplicity, I’ll only cover the image captioning part here.
A gentle introduction to Image Captioning
Image captioning refers to the task of automatically writing captions of images in natural language. It is widely believed to be a hard AI problem and it has garnered significant interest from some of the stellar research groups in the field. Among companies working in AI, only Google Research, Microsoft Research, and Facebook AI Research more recently, seem to have made some progress in this. But it’s still part of research labs and will probably take some more time before it’s ready for prime time.
While researching we found that one of the key problems in the space is automatically describing the content of an image. Many researchers see image captioning as the basis for more sophisticated artificial intelligence systems that can see, hear, speak, and even understand the way we human beings do.
While there has been a lot of progress in the field of object classification, localisation and detection in recent years, however, accurately describing a complex scene requires a deeper representation of what’s going on in the scene, capturing how the various objects relate to one another, and translating it all into natural-sounding language.
While as human beings we are tuned to easily explain a complex setting in simple words, the task gets very difficult for computers. However, we have started identifying the key concepts required to solve this problem in a very effective way.
Also read: Why building a disruptive technology company from India is hard and how you can do it anyway
Our team has developed an advanced AI system that can easily and automatically produce captions to accurately describe images the very first time it sees them, after some initial training.
We believe that this system could eventually help visually impaired people understand pictures and video content, and maybe help robots navigate natural environments. And obviously there can be a lot of other use cases of this technology beyond what we can think of today.

How did we do it?
For a while now we’ve been working with various image recognition problems. Last summer we experimented with scene recognition problems in computer vision for the first time. Around that time we also started looking at scene understanding at a deeper level and found it to be quite fascinating.
During this time we thought that if we could build a system that understood the whole scene as well as we do, we would get closer to building a powerful AI system. We worked ahead and identified the problem as image captioning and discovered that only few of the companies had tried this before us. These included Google Research and Microsoft Research and more recently Facebook AI Research.
We started building our own system from scratch as we saw there was a lot to be done in this relatively nascent area of research in Artificial Intelligence. We believed that we could help move the field forward with our own contributions.
As for the process, we basically merged some of the recent computer vision and language models into a single jointly trained system, taking an image and directly producing a human readable sequence of words to describe it. We made use of a convolutional neural network and a recurrent neural network as our building blocks to build this joint model.
This type of model has worked well in machine translation probelms where two recurrent neural networks can be used for translating from one language to another. The captioning system works a bit differently, but essentially uses a similar approach. Our software currently can write a caption in English language to describe the picture. As you see below, the early results show a lot of promise.

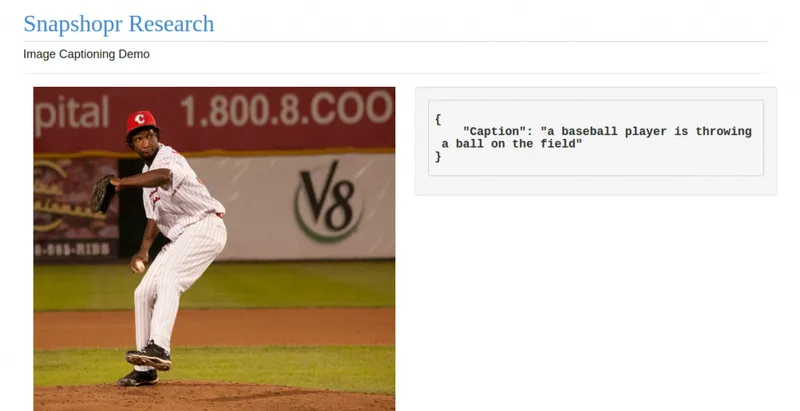
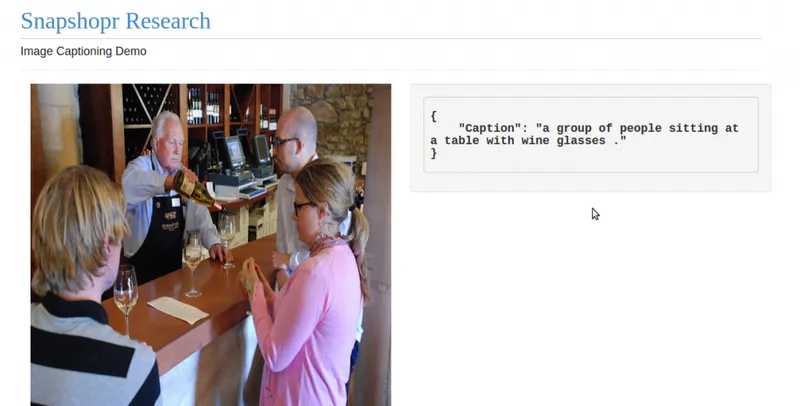
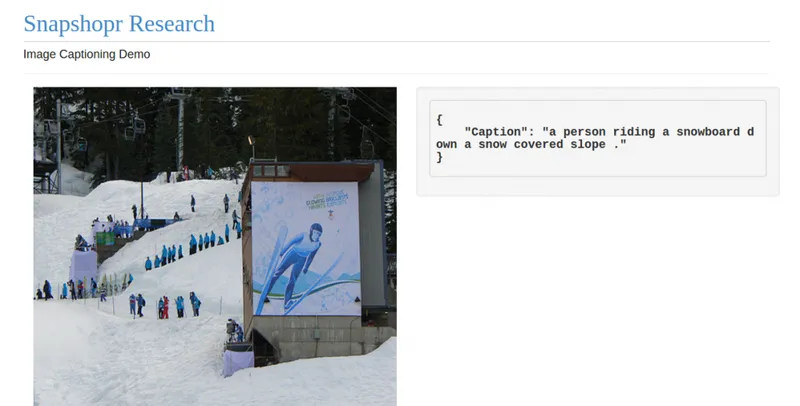
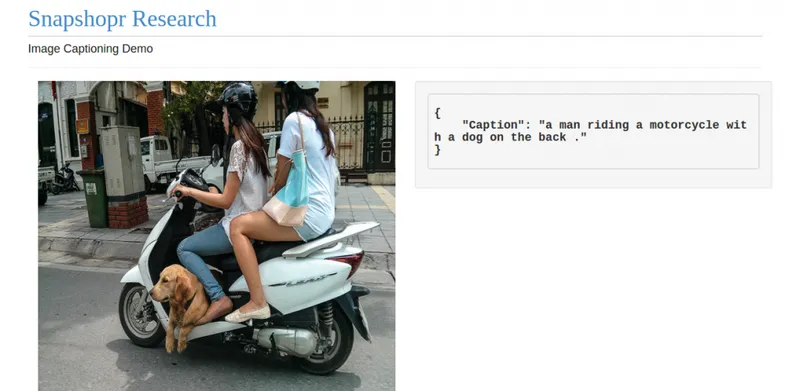
The system, as you can see above, failed to produce a coherent description for the last example. But we believe it will learn to generate more detailed and accurate descriptions with better training and improvements in our model design .
This is just a start. Every day we are learning something new about intelligence, memory, and probably consciousness too. And we want to bring our understanding to light with the help of software that helps people in all sorts of ways. And yes, we have no intention of building software which could be used by bad people to power Terminators.

About the AuthorNavneet Sharma is an entrepreneur and founder at AI startup SnapShopr. He is an ardent believer in design thinking as a powerful tool to solve complex problems. He is a movie buff and believes that being a founder and a filmmaker have a lot in common. He writes his personal blog at www.medium.com/@navsha and can be reached on Twitter @NavSha
(Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the views of YourStory)




