

How machines seeing the world is changing the world they see

Vision is one of the most important senses we have as human beings — it is said almost two-thirds of our brain’s processing power is dedicated to vision and vision-related functions. It’s what kept our ancestors alive in the Stone Age and it’s what keeps us safe while driving or crossing a busy road. The eyes capture more information than any other sensory organ, which means that much of the brain’s working capabilities are spent in processing and making sense of what the eyes see, allowing us to react, make decisions and use our motor skills.
It is no wonder then, that for a long time now, we have tried to replicate the power of vision in various forms: from the time that pre-historic human beings drew on the walls of caves in a bid to store an image outside of the human mind to the camera that slowly yet steadily gave this power to the masses in ever-simplified ways and form factors.
Reproducing the capability of the human visual system in the digital world has been challenging, to say the least. First, we needed great cameras that could capture high quality images and videos. Next, we needed the computing power and storage to make sense of the voluminous data coming in from these cameras. Finally, to make decisions and carry out an action in ‘real time’, we needed to be able to do all of these extremely fast.
Let’s first talk of cameras — or at a more general level, sensors that capture images and videos. They needed to be good enough and cheap enough to be used widely. Thanks to widespread smartphone adoption in the past decade, we ship billions of cameras every year along with phones. These cameras have become very good — they are high-resolution and produce great image and video quality across various light conditions and wavelengths, right from IR to the complete visual spectrum. Given the scales of economy and the advances in technology, these camera modules have also become very cheap. Ever-thinning smartphones have also driven down the size of these cameras — which enables them to be used across a variety of applications.
The second issue is the storage and processing of the data that gets generated from these sensors. Advances in semiconductors and chip manufacturing have exponentially increased computing capabilities (Moore’s Law) and storage capacity (from magnetic tapes to transistor memories). But to process the volumes of data from a camera, you needed to have entire server farms of computers and lots of storage running in data centers or on a cloud.
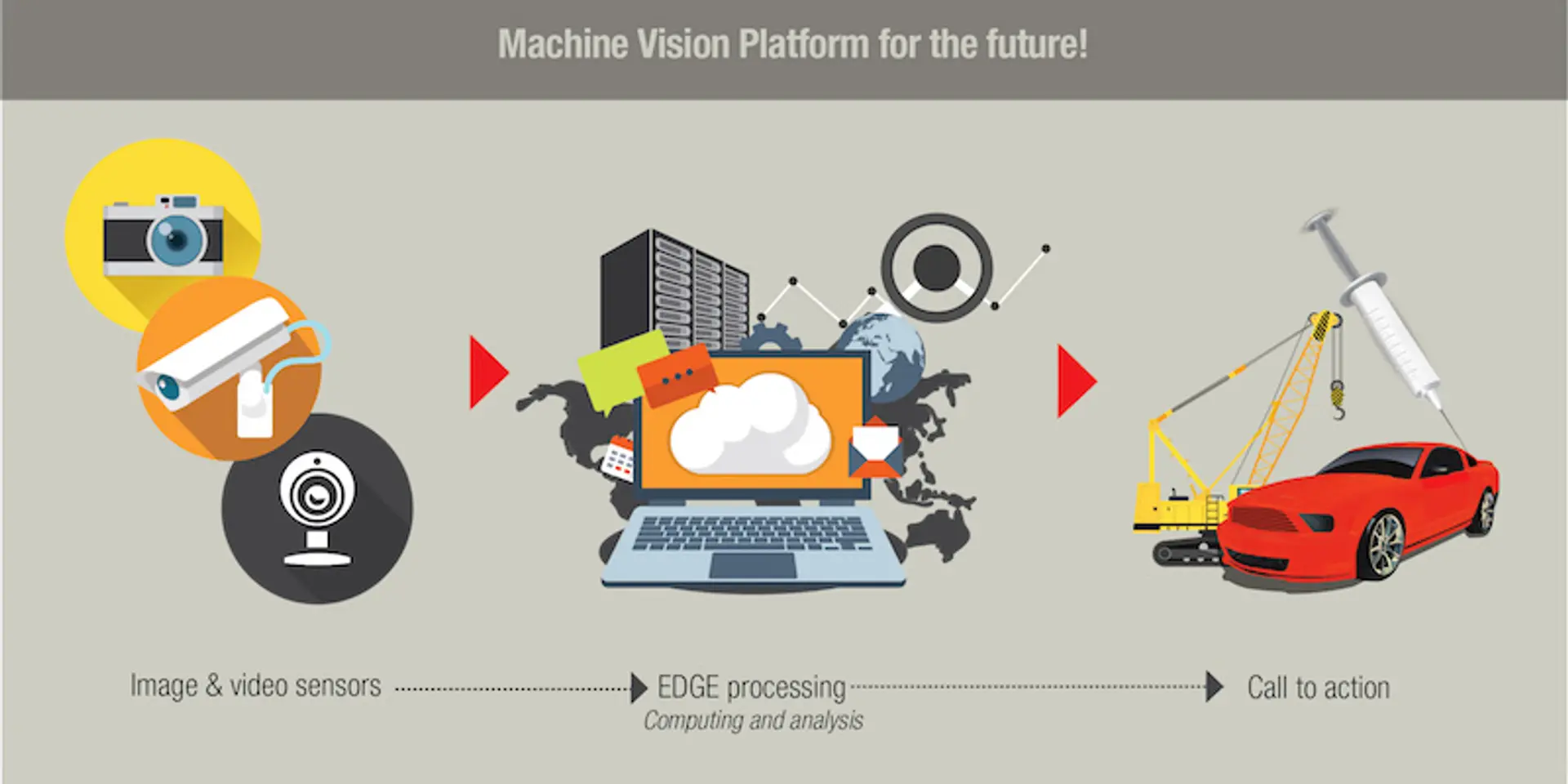
Which brings to the last part of the problem: to make sense of the videos, detect any patterns and to act up on it — all in real time — it required an expensive array of computers and storage. Routing large amounts of video data to a data center and back was not a viable option except for applications like defense or high-end surveillance. Processing and decision-making needed to be done at the ‘EDGE’ — or closer to where the action was and where the cameras were.
In the last few years, AI, specifically deep learning using cognitive neural networks, have unlocked huge potential in processing and detecting complex patterns in images and videos. We have only scratched the surface, but today it is possible to do several deep-learning-led applications on videos and images in real time using GPUs and processors from Qualcomm, Nvidia, Intel and the others.
This has fundamentally opened up a new platform, or an architecture, or a template, to look at various problems and solve these in a way that simply wasn’t possible before. We may be getting closer to ‘replicating’ a human vision type system in the digital world.
Let us look at some of the examples today. The biggest one is the autonomous drive system deployed in Tesla and other autonomous vehicles. There is a suite of sensors capturing video information across all directions. The videos are then processed and sent through complex models: the view of the road is ‘understood’ digitally — with lanes, road information, vehicular and passenger traffic, all of them detected mostly locally in the car using the AI and machine learning (ML) models. Based on what is analysed, there is localised action — control of the steering wheel, accelerator and the brakes. In real time. Most of this is done at the ‘EDGE’ — in the car; while driving. Obviously, the video captured is sent to the servers to train the learning and detection model, but a significant part of the action is happening in the car itself. Just like a human vision system. It is by no means perfect but it is getting there.
Take surveillance and monitoring as an example. The existing paradigm is to record and transfer hours of video to a storage device where it can be processed offline. Well not anymore. With the ‘EDGE’ machine vision system, it is now possible to look for anomalies and intrusions while capturing the videos ‘live’. Startups like UncannyVision already have products in this area.
Look at driver monitoring solutions for trucks and fleets. Companies like Nauto and Netradyne have a platform similar to the machine vision system described earlier to detect driving distractions and anomalous behavior in real time and take immediate action.
Using this new architecture model, we are seeing solutions to problems that haven’t been addressed ever before. We are seeing products and solutions that detect patterns and understand behaviors in variety of areas, ranging from online education to manufacturing lines, retail locations and many more.
It’s worth pausing and considering these developments. For the first time in history, we have all the building blocks in place. They may not be perfect but they are very good, and improving every minute. We have cameras that can capture videos vividly and in a cost efficient and compact fashion. We have computing and storage elements that can crunch these data using deep learning AI models in real time. With enough data flowing through these ML models, they are learning faster than ever before and generating richer insights in real-time from increasingly complex data. The potential applications are endless, and indeed, mind-boggling.
What remains to be seen is how these endless possibilities are combined to usher in a new era in computing. Perhaps not quite in the lightning-fast league as the human eye-brain-spine triumvirate, but close. Very close.