



Why do we need to check outbound links? First of all, to monitor the adequate positioning of your site in the network, as well as to analyse the interlinking of your site. The first part of the article describes searching for links and building graphs of interconnection, the second part is about building a kind of site map - internal linking to make sure that all your pages are interconnected with each other and form a flat structure.
Step 1. Get all outbound links to your site.
First you need to parse your site. To do this, you can develop either your own parser or use a ready-made software solution. In the framework of this article, the second (faster) method will be implemented - by using ScreamFrog. To do this not much time or effort is actually needed. First, let’s open ScreamFrog and increase processing speed, which depends on your hardware.
Figure 1 – Choosing the configuration settings window

Figure 2 –Set the optimal number of threads
You also need to get all the content from the site. To make this let’s configure the user settings.

Figure 3 – Selecting the custom extraction window.
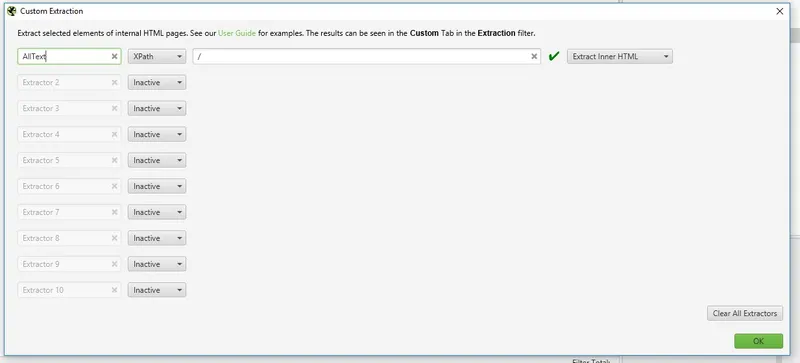
Figure 4 – Fill in the tab wanted, using XPath regular expressions.
Then let’s specify the site which pages to be checked. In my case, this is https://casino-now.co.uk project, where I’m working as data science researcher.
When the load is complete, you will see the following screen:
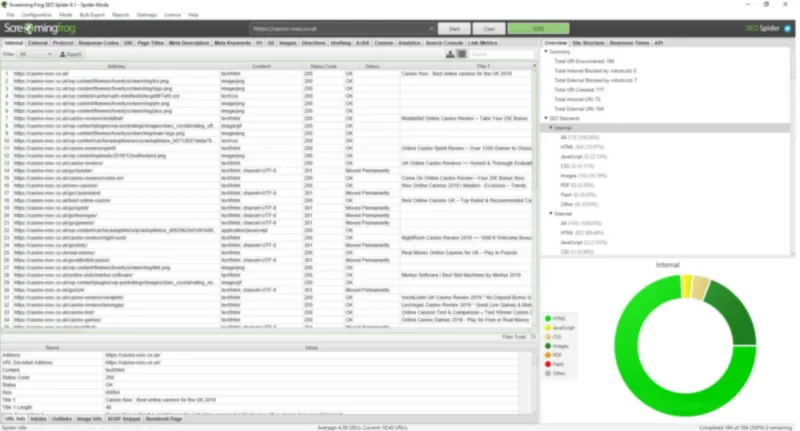
Figure 5 – ScreamFrog’s results
Next, set the filter that only html pages are relevant – this’s to exclude possible rubbish from the analysis (pictures, CSS files, java scripts and etc). Then save the results. Hence, you obtain a table with the main parameters of the site’s content.
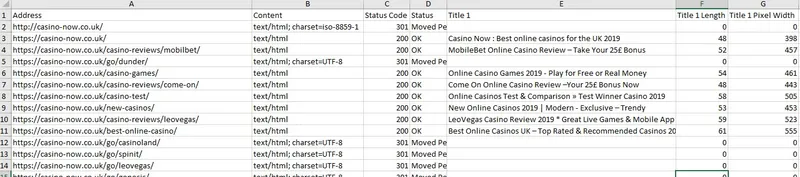
Figure 6 – Fragment of the data
Don’t forget to check how the user’s execution has worked:
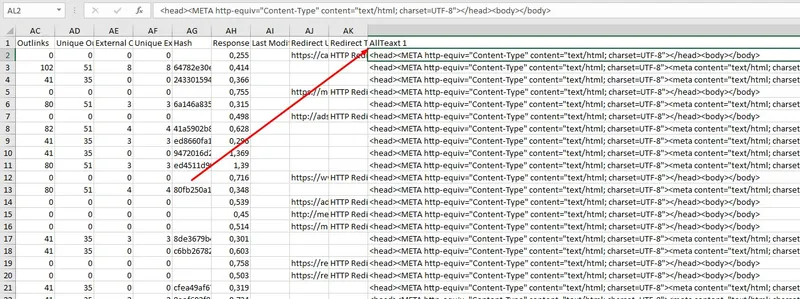
Figure 7 – Fragment of the data
You may notice that AllText 1 column contains the full html document with pages. Now let’s analyse the textual information received. To do this - clean up the received text and select all the links. Software implementation is presented below:
import pandas as pd
import re
df = pd.read_excel("internal_html.xlsx")
text = ' '.join(df["AllTeaxt 1"].values.tolist())
allLinks = re.compile('<a(.*?)</a>' , re.DOTALL | re.IGNORECASE).findall(text)
href = re.compile('href="(.*?)"' , re.DOTALL | re.IGNORECASE).findall(text)
goodlinks = []
for link in href:
if link.startswith("/"):
goodlinks.append("https://casino-now.co.uk"+link)
else:
goodlinks.append(link)
Supergoodlinks = []
for link in goodlinks:
if link.startswith("http"):
Supergoodlinks.append(link)
df = pd.DataFrame(Supergoodlinks)
df = df.drop_duplicates()
writer = pd.ExcelWriter("Links.xlsx")
df.to_excel(writer, 'Sheet1',index = False)
writer.save()
Thus, you not only receive interlinking and external links, but also links like https://casino-now.co.uk/go/leovegas/.
Step 2. Analysis of outbound links
Now from the pool of all links sourced of the project, let’s choose available links from the profile of your project and will get a list of domains referred. To do this - use ScreamFrog again.
We will upload the list of acceptors URLs, for this - select settings to process a list of URL addresses.
Figure 8 – Switching the software for processing a list of documents
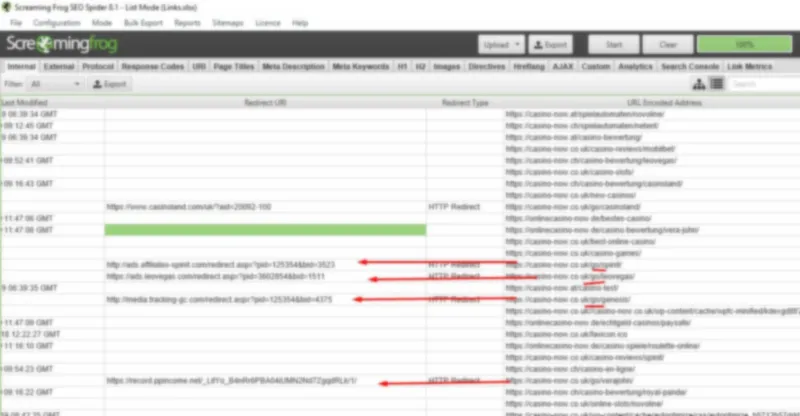
Figure 9 – Search for unaccounted links to external domains
Then you can compile a complete list of acceptors URLs. I implement the networkx library for visualization. Software implementation is presented below.
# libraries
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
# Build a dataframe with 4 connections
ddf = pd.DataFrame()
ddf['from'] = "casino-now.co.uk"
ddf['to'] = df['RealAdress'].apply(DomainExtract)
ddf = ddf.drop_duplicates()
# Build your graph
G = nx.from_pandas_edgelist(ddf, 'from', 'to')
# Plot it
nx.draw(G, with_labels=True)
plt.show()
As a result, you get a graph where the site under study is located in the centre, with links leading to external domains.
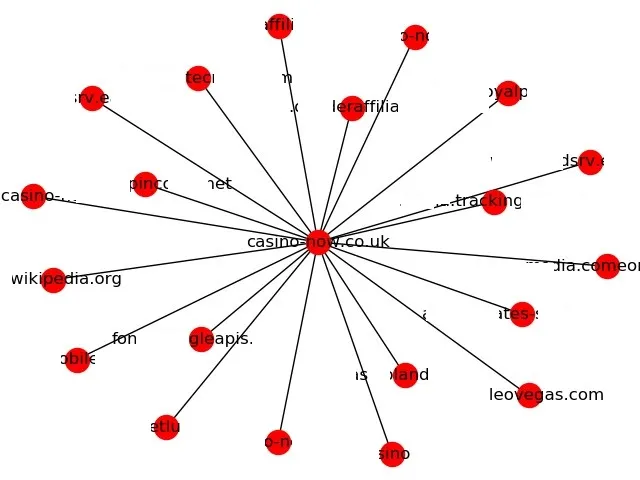
Also, this software package has the option to upload your graph in the form of a web document, which will make it more customer-oriented and will help working with older projects having a large number of links. You can find the full software implementation on my Github https://github.com/TinaWard.
Step 3. Analysis of interlinking
In order to check the interlinking, it’s necessary to form a data frame so that domain name of the acceptor and donor links coincide. Software implementation is presented below.
import pandas as pd
import re
df = pd.read_excel("internal_html.xlsx")
allLinks = pd.DataFrame()
allLinks['from'] = ""
allLinks["to"] = ""
for index in range(len(df)):
href = re.compile('href="(.*?)"' , re.DOTALL | re.IGNORECASE).findall(df["AllTeaxt 1"][index])
goodlinks = []
for link in href:
if link.startswith("/"):
goodlinks.append("https://casino-now.co.uk" + link)
else:
goodlinks.append(link)
Supergoodlinks = []
for link in goodlinks:
if link.startswith("http"):
Supergoodlinks.append(link)
for link in Supergoodlinks:
ddff = pd.DataFrame(index = range(1))
ddff['from'] = df['URL Encoded Address'][index]
ddff["to"] = link
allLinks = allLinks.append(ddff)
allLinks['dom'] = allLinks['to'].apply(DomainExtract)
allLinks = allLinks[allLinks['dom']=='casino-now.co.uk']
allLinks = allLinks.drop_duplicates()
Since the set of links for analysis is large enough, use the dynamic realization of the graph. As a result, we got the following graph.
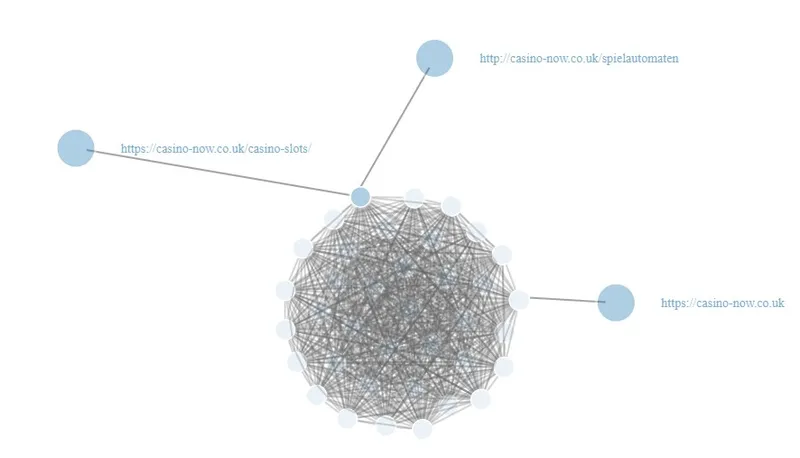
At first glance, it doesn’t provide any useful information, however, observations that are out of the general mass are important for analysis. For me, these are web documents that are linked with only one page. So, in this case a developer should research why these three pages aren’t linked with the rest.
The next stage is the analysis of insufficient interlinking. To make this, the obtained pool of pages is compared with the unique pages of recipients.
df = pd.read_csv("YOUR_URLS.csv")
allLinks = allLinks.drop_duplicates(['to'])
allLinks.index = range(len(allLinks))
df['cool'] = 0
for index_big in range(len(df)):
for index_little in range(len(allLinks)):
if df['Address'][index_big] == allLinks['to'][index_little]:
df['cool'][index_big] = 1
df = df[df['cool']== 0]
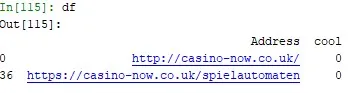
As a result, the df value contains a list of URLs that aren’t interlinked within the project. For my case, the outcome is shown in the figure. As you can see, the results confirm abnormality observed in the previous graph.
Conclusion
Analysis of the website’s outbound links and interlinking is important process necessary for the qualitative growth of your project. With the help of several libraries and lines of code, you can develop your own tool that allow you to perform this analysis automatically according to the tasks, highlighting only pages that need special focus. Full code you can find here: https://github.com/TinaWard/Interlinking
Thanks for your attention.
Share your feedback and comments, looking forward for that:



