

This is a user generated content for MyStory, a YourStory initiative to enable its community to contribute and have their voices heard. The views and writings here reflect that of the author and not of YourStory.

Speech-to-Text using Convolutional Neural Networks


This is a user generated content for MyStory, a YourStory initiative to enable its community to contribute and have their voices heard. The views and writings here reflect that of the author and not of YourStory.

Deep Learning beginners quickly learn that Recurrent Neural Network (RNNs) are for building models for sequential data tasks (such as language translation) whereas Convolutional Neural Networks (CNNs) are for image and video related tasks. This is a pretty good thumb rule - but recent work at Facebook has shown some great results for sequential data just by using CNNs.
In this article I describe my work for using CNNs for Speech-to-Text based on this paper here. I have also open-sourced my PyTorch implementation of the same paper.
RNNs and their limitations
Quick recap - RNNs process information sequentially, i.e., they make use of the sequential information present in the data where one piece of information is dependent on another, and they perform the same operation on each and every element of the sequence. This property of RNNs enables a network to represent complex dependencies between elements in a sequence which is pretty useful for tasks such as speech recognition.
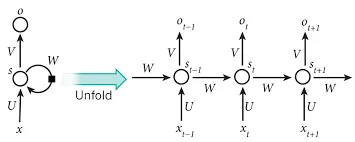
Fig 1: How RNN unrolls when the sequence is passed to it. Here, ‘x’ denotes input and ‘o’, the output.
However, this advantage comes with two limitations. These dependencies make the model unwieldy as every step is dependent upon the previous operation - so calculation of nodes cannot be divided across processors and have to be done in a sequential manner. This also makes training and inference of the RNN based models a little slow. RNNs also restrict the maximum length of the sequences as all representations then have to be equal to the largest input sequence.
Using CNNs for sequences
CNNs are routinely used for image-related tasks but two papers, which can be found here & here, extended their utility- as encoders for sequential data.
In the first paper the CNN encodes the information from the voice-features. This data is sent to a convolution layer with kernel-size of 1 which also acts as a fully connected layer. This finally gives softmax probabilities of each character that can be placed in the transcription
In the second paper the CNN encodes the information from the image and sends that data to the RNN based decoder which decodes the data and outputs the corresponding text from the image.
This suggests that Convolutional Network can perhaps replace Recurrent for speech-to-text tasks as well.
CNN alleviates both the limitations of using RNNs. Since the input to CNN is not dependent on previous time step calculations can be broken down and done in parallel. This makes training as well as inference much faster compared to the RNN based models. As a CNN learns fixed length context representations and stacking multiple layers it can create larger context representation. This gives the CNN control maximum length of dependencies to be modeled.
A final advantage of using CNNs is that we are much more familiar with them owing to our large body of work in image and video analytics.
Using CNNs for Speech to Text
A speech-to-text pipeline consists of a front-end that processes the raw speech signal, extracts feature from processed data, and then sends features to a deep learning network.
The most widely used frontend is the so-called log-mel frontend also called MFCC, consisting of mel-filterbank energy extraction followed by log compression, where the log compression is used to reduce the dynamic range of filterbank energy. But we used PCEN for our implementation as it led to better accuracy for us. This is explained in detail here.
Output of this frontend usually feeds into some RNN based encoder-decoder architecture which converts these features into corresponding transcription. We used Wav2Letter implementation in NVIDIA OpenSeq2Seq to replace RNN with a CNN architecture.
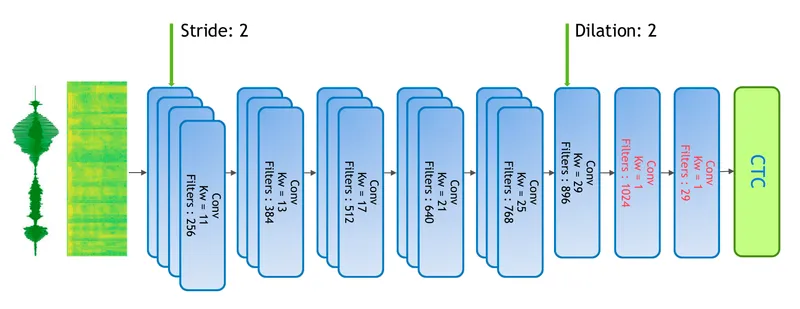
Fig 2: A fully convolutional network for speech to text.
Nvidia’s implementation was in TensorFlow, which is a great framework, but, bracing the wrath of TF lovers, I dare say I prefer PyTorch - primarily because I find the PyTorch framework more intuitive and easy to run experiments in.
Digging through the internet we found no similar implementation in PyTorch. So we decided to implement the Wav2Letter in the framework ourselves.
We have also open-sourced the entire code developed by us. You can find it here - https://github.com/silversparro/wav2letter.pytorch. As mentioned above, we have replaced MFCC-based front-end with PCEN. Please do check out the open-source implementation and feel free to contribute further.
Accuracy results
This model currently gives the same accuracy as a RNN-based model but with 10-fold decrease in training time and a similar reduction in inference time. This is a work in progress and we shall keep updating the blog with the results of our experiment.
References: Wav2Letter, CRNN, DeepSpeech2, PCEN, AGC, Nvidia wave2Letter, Wav2Letter-lua
Silversparro Technologies aims to help large enterprises solve their key business problems using expertise in Machine Learning and Deep Learning. Silversparro is working with clients across the world for Video Analytics, Computer Vision, Voice automation use cases working for manufacturing, BFSI, healthcare verticals etc. Silversparro is backed by NVIDIA and marquee investors such as Anand Chandrashekaran (Facebook),Dinesh Agarwal (Indiamart), Rajesh Sawheny (Innerchef) etc.
Silversparro is founded by IIT Delhi Alumni – Abhinav Kumar Gupta, Ankit Agarwal and Ravikant Bhargava and is working for clients such as Viacom18,Policybazaar, Aditya Birla Finance Limited, UHV Technologies etc.