

With freemium tweet-to-use monthly subscription models, JobsPikr aims to democratise access to public job data


“Public data, in theory, is meant to be accessible to everyone. But, in practice, even finding it can be near impossible…” notes a recent report from FastCoDesign. Bengaluru-based PromptCloud and its sister initiative, JobsPikr, aim to help people find and make sense of public data.
'Water, water everywhere, nor any drop to drink,' is an oft quoted line from the famous poem ‘The Rime of the Ancient Mariner’. While sailors out in the sea are surrounded by water on all sides, they can’t consume the water directly because of its salty nature.
Drawing a similar comparison in the digital world, data volumes are exploding and more data has been created in the past two years than in the entire previous history of the human race. But, while data is more accessible than ever before, making sense of unstructured ‘big data’ is a big task for startups and enterprises.
Operating for close to six years, PromptCloud is a Bengaluru-based company that specialises in custom and large-scale web data extraction. It aims to make it easier for companies to gather and access publicly available data from multiple sources and geographies and make sense of them. Here is their story.

Story so far

Prashant Kumar, Founder of PromptCloud, graduated from IIT-Kanpur and worked at Yahoo! for a year. Looking at the big data landscape, he decided to venture out on his own and start PromptCloud. As a data solutions company, PromptCloud notes that it has clients from all over the world and in different sectors—including enterprises, startups and SMEs from various sectors like e-commerce & retail, travel & hospitality, finance, healthcare, marketing & business research, analytics.
Earlier this year, Prashant and Arpan Jha co-founded JobsPikr, a subsidiary of Promptcloud, to focus on data needs in a niche category—the jobs space. Arpan has a masters in Software Engineering from Carnegie Mellon University and had earlier worked at some of the Big Four, like Deloitte and PwC.
From JobsPikr 1.0 to 2.0
The first version of JobsPikr was launched by PromptCloud in May 2017 to help job boards, recruitment agencies and labour market research firms access publicly available job data present on company websites in a ready-to-use format. The team relied on feedback from early users and suggestions from communities such as ProductHunt and Betalist to overhaul their platform and launch JobsPikr 2.0.
Now, users can select the sites to get job feeds from the geography and/or industry they serve. For example, a recruitment agency catering to Australian energy market can get job data from the websites of Australian companies operating in the energy space.
The previous version offered job feeds based on pre-packaged bundles of sites. It restricted users from selecting only the sites they needed, as the bundles came with at least 50 sites. The upgraded version 2.0 has a more flexible site selection process—it allows users to handpick certain sites or select all sites from relevant region and industry.
The startup has an auto extract algorithm that extracts job-related details from career pages and further from job listings. A company spokesperson noted,
A typical job would consist of fields like job title, location, date the job was posted and job description. This data can be downloaded in any of CSV, XML or JSON formats depending on your application of these feeds.
JobsPikr deploys automated crawlers powered by machine learning techniques to extract latest job listings from the career pages of company websites. Customers have the option to select individual websites or all the sites from the geographical region and industry as per their requirement. Once subscribers opt for one of their subscription plans, JobPikr deliver the the data feed segregated by geographical regions and industries. Customers can directly download the data or publish the data through JobPikr’s REST API.
Revenue model
The JobsPikr team noted that based on feedback they have tweaked their revenue model too. JobsPikr realised that many of their existing subscribers were companies that catered to specific industries, such as software, telecommunication, healthcare.
Although they already had a provision to select sites based on geography, they added filter to help them select industries as well. This helped them make the subscription fee more affordable by directly mapping it to the number of sites selected by customers. A spokesperson added,
We also made significant improvements to the core machine learning algorithm for data extraction and more than doubled the number of sites available in our current pool.
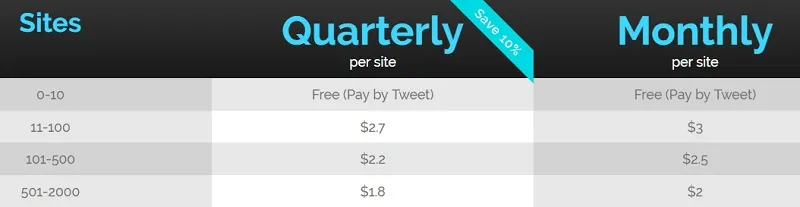
While JobsPikr has monthly and quarterly subscription plans for customers, they also have an interesting freemium offering available, which can be unlocked by tweeting. Users can get free job feeds for upto 10 websites for three months by tweeting about JobsPikr. They can then continue with this subscription indefinitely by tweeting again as needed.
Sector overview and future plans
The term ‘web scraping,’ which generally refers to wholesale theft of website content has a bad connotation, and according to a recent report by Distil Networks, two percent of online revenue is lost as a result of web scraping. The second main use for web scraping is research.
According to the same report, 26 percent of companies that hire web scrapers use web scraping bots to gather research on listening services that monitor consumer opinions about products and companies. Some of the active players in the web scraping space include Scrapinghub, Screen-Scraper, Mozenda and Diffbot.
Focussing on just the jobs space, Google in June 2017 launched an AI-powered job engine that let people search for jobs across virtually all of the major online job boards like LinkedIn, Monster, WayUp, DirectEmployers, CareerBuilder and Facebook and others.
Currently, JobsPikr's focus areas include the US, Europe, Australia and India, and it aims to add regions in the future. It is also planning to build specialised solutions for more verticals like travel, similar to what it did with JobsPikr for the HR industry. The company spokesperson noted,
With JobsPikr, we aim to democratise the access to publicly available job data on the web for businesses across the world, and help them focus on growth without worrying about data acquisition.
Website- JobsPikr
Related read: Big data analytics makes its way into the Indian agriculture sector through SatSure