

This Bengaluru startup is competing with Silicon Valley giants with machine learning feature store
Scribble Data is a machine learning operations product company startup that has developed a modular feature store called Enrich with multiple pre-built feature engineering apps.


A visit to DMart or Reliance Retail in India on any given day would make one think about Black Friday sales. The limited manpower in stores often falls short to tend to the swarm of shoppers in Indian retail stores.
To solve the issue, strives to provide automated and customised solutions for retail businesses to tend to the demand and needs of every customer that walks in through their door.
The startup offers retail chains real-time inventory management, identifies customer shopping trends, and provides personalised recommendations.
What does it do?
Scribble Data helps businesses build machine learning (ML) applications for making their daily operations hassle free and for creating more market-worthy ML features. It offers a feature app store called ‘Enrich’ where teams can collaborate and reuse the features to build lightweight data apps.
Some of the apps in the store include dashboards, intelligent reports, and search interfaces that simplify, standardise, and speed up the machine learning models for organisations to deploy in the market. ‘Enrich’ competes with the likes of Google’s Vertex AI, Amazon’s SageMaker, Databricks, Uber’s Michelangelo, and Facebook’s FBLearner.
The startup’s clientele also include companies from sectors such as fintech, edutech, healthcare, and consumer packaged goods.
“Data is driving the world today,” Venkata Pingali, Co-founder of Scribble Data tells YourStory. “Today, most organisations rely on machine learning applications for their daily operations. But these applications are complex and need high-quality datasets. Teams often do not have a long time, a huge team or an enormous budget to build such complex stuff. Scribble Data helps them to build their required applications in a short period and with comparatively fewer resources.”

Why Scribble Data?
Venkata was initially inclined towards pursuing software engineering academically. After graduating from IIT Bombay, he pursued MTech from the University of Utah and later his PhD in Computer Networks from the University of Southern California.
However, Venkata changed gears and decided to focus on the practicality of software engineering when he met Indrayudh Ghoshal, a McGill University alum who shared his passion for data software. The two data enthusiasts were working on different projects during a campaign when they looked at the organisations such as Facebook, Amazon, Netflix, and Google that develop ML products and applications. They realised that there was a dearth of clean and efficient data to run ML programmes.
So, they decided to found Scribble Data in 2017.
Scribble Data raised $2.2 million in seed funding in March 2022 led by Blume Ventures. The round also saw participation from Log X Ventures and Sprout Venture Partners, and individual investors such as Vivek N Gour (former CFO, Genpact) and Ganesh Rao (Partner, Trilegal).
Commenting on their investment in Scribble Data, Anirvan Chowdhury, VP, Blume Investment team, said,
"With more organisations effectively becoming data companies, there is a proliferation of high quality, compliant feature sets for ML and Sub-ML use cases in an organisation. And those feature sets will need to be managed, re-used and served in the most effective manner in ML models or other Sub-ML use cases."
Scribble Data

The intersection
Venkata says, “These big companies have a clear sight of their end goal and what kind of applications they want. But there is no way of verifying that they are using the correct datasets for their apps to run efficiently. It is only when the output is in front of them, after almost a year, do they determine its success or failure. Today, teams do not have that much time and they want their results quickly. The simple feature apps of Enrich solve this problem.”
Although Venkata and Indrayudh co-founded Scribble Data in 2017, it took them two years to come up with the idea of their features’ store ‘Enrich’ in 2019.

Today, the startup has a team of 11 people operating from two offices – Bengaluru and Toronto, Canada, and catering to a clientele across India, Europe, and Africa, including some Fortune 100 customer packaged goods companies and e-commerce majors.
Over the past year, the team saw 300 percent revenue growth with their typical customer engagement being around $25,000 - 50,000 per use case per year.

Challenges
Venkata says that an Indian company competing with big names in Silicon Valley as an ML feature store comes with its own perks and challenges. Exploring a niche segment called sub-ML within machine learning to build the feature apps meant the team did not have any predecessors whom they could reference.
“We didn’t have enough guidance while building our final product. Although we came together in 2017, the clarity about our feature store came only in 2019. Most of the work was based on intuition and experience with potential clients in the market,” says Venkata.
The pandemic also posed a challenge in the hiring process and the adaptability to the new remote work environment. However, it also boosted the demand for the platform as most organisations were looking for easy-to-build ML models to ensure smooth operations despite being spread across remote locations.
Market perspective and future
While feature engineering is not a new concept in machine learning, the market for feature stores took its own sweet time to gain traction. One of the pioneering ML feature stores was ‘Michelangelo’ developed by Uber in 2017. Venkata says that the entry of Michelangelo changed the trajectory of the marketspace for machine learning.
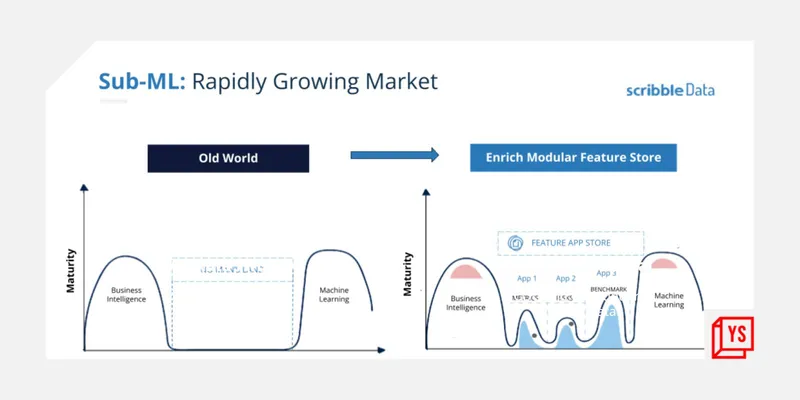
Market perspective by Scribble Data
According to Fortune Business Insights, the global machine learning (ML) market is projected to grow from $21.17 billion in 2022 to $209.91 billion by 2029, at a CAGR of 38.8 percent.
“We have witnessed tremendous changes in terms of demand and use cases of ML in the past five years. Companies are understanding the value of maintaining good data sets for ML models to work efficiently. This, in turn, increases the demand for features stores like that of Scribble Data,” reflects Venkata.
He believes that the use cases of machine learning would boom 50 to 100X. Scribble Data plans to scale up its marketing and invest in strengthening the team. The company is keeping North America as the target market space.
Edited by Kanishk Singh